GB2312 字符集与编码
前面的一些篇章更多谈论了 Unicode 的相关话题, 虽然也有提到 GBK 等编码, 但都没细说, 这里打算系统说一下. GB 系列包括 GB2312, GBK, GB18030.
前面已经提过, GB=Guo Biao=国标=国家标准, 至于所谓的 2312 就是一编号了, 没有其它特别的意义, 18030 类似.
最早的是 GB2312, 我们从它开始说起.
GB2312 概述
以下为一简介(官方文档见"国家标准化管理委员会"网站: 信息交换用汉字编码字符集 基本集(Code of Chinese graphic character setfor information interchange--Primary set) GB/T 2312-1980 ):
GB 2312-1980, 全称<<信息交换用汉字编码字符集 基本集>>, 由国家标准总局于 1980 年 3 月 9 号发布, 1981 年 5 月 1 日实施, 通行于大陆.
新加坡等地也使用此编码.
它是一个简化字的编码规范, 也包括其他的符号, 字母, 日文假名等, 共 7445 个图形字符, 其中汉字占 6763 个.
作为一个编码字符集而言, 前面也曾说到, 它采用了所谓的二维区位编号, 下面是一个概览图:

它是一个 94×94 的表格, 理论上有 94×94=8836 个空间.
横的叫 区, 竖的叫 位, 总共 94 个区, 每个区有 94 个位. 区和位的编号都从 1 开始. 可以看到粗略有三大部分.
94 个区
中间黑色的主体部分即是汉字区了, 具体为16-87 区, 共 87-16+1=72 个区, 理论空间为 72×94=6768.
从上图中可以看到中间有 5 个编码为空白(中间靠右边部分, 55 区最后 5 个位), 所以总共有 6768-5=6763 个汉字.
一级汉字与二级汉字:

第 16-55 区: 一级汉字, 3755 个(以拼音字母排序)
第 56-87 区: 二级汉字, 3008 个(以部首笔画排序)
最下面的 88-94 区是有待进一步标准化的空白区.
关于前面的 01-15 区, 下图为概览图左上角的局部放大图:

- 01-09 区为符号, 字母, 日文假名等, 部分区还有空白位.
03 区即是对应 ASCII 字符的全角字符区. 输入法的全角模式下输入的即是这些字符.
10-15 区也是有待进一步标准化的空白区.
各区的一个具体情况:
第 01 区: 中文标点, 数学符号以及一些特殊字符
- 第 02 区: 序号
- 第 03 区: 全角西文字符
- 第 04 区: 日文平假名
- 第 05 区: 日文片假名
- 第 06 区: 希腊字母表
- 第 07 区: 俄文字母表
- 第 08 区: 中文拼音字母表
- 第 09 区: 制表符号
- 第 10-15 区: 未定义
- 第 16-55 区: 一级汉字(以拼音字母排序)
- 第 56-87 区: 二级汉字(以部首笔画排序)
- 第 88-94 区: 未定义
区位码
在上图中还标出了一个汉字 啊, 它就是 GB2312 方案中的天字第一号汉字, 它处于 16 区 01 位上, 所以它的区位码即是 1601.
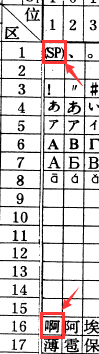
所谓区位码就是这一 94×94 的大表格中的行号与列号了, 均从 1 开始编号.
第一个字符 0101 为"全角空格"(图中显示为 SP(space)).
国标码
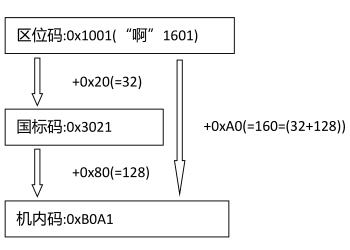
将区位码的区和位分别加上 32(=0x20)就得到了国标码.
"啊"的区位码是 16-01, 分别加 32, 得到 16+32-01+32=48-33, 即是国标码.
当然, 你通常应该写成 16 进制, 48-33 即是 0x30-0x21, 所以 3021 即是"啊"十六进制的国标码, 使用两字节保存, 30 为高字节, 21 为低字节. 如下:
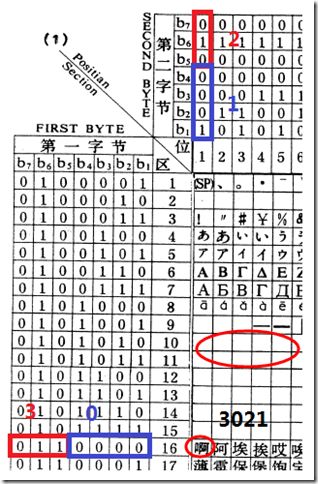
GB2312 方案规定, 对上述表中任意一个图形字符都采用两个字节表示, 每个字节均采用七位编码表示.
如上图所示, 只用了 7 位, 这即是说最高位就是 0 了.
但为何不直接采用区位码呢? 为什么要加 32 呢? 你也许还记得前面说到 ASCII 时, 前面 32 个字符是控制码, 中文系统自然也不能少了这些控制码, 为了不与这些控制码冲突, 加上 32 就能跳过它们了.
一字节有 128 个空间, 128-32=96, 实际上, ASCII 中第 127 个也是控制码(DEL, 删除), 再减去就还有 95 个有效位, 再加上区位从 1 开始, 又损失了一位, 所以最终只有 94 个有效位了, 这也是前面为何是一个 94×94 的表格.
国标码的定位实际应该是与 ASCII 一致的, 是作为国家信息交换的标准码. 从设计上看, 它并没打算兼容 ASCII, 它已经把 ASCII 中的字符收录了过来, 不过是作为所谓的全角字符来看待, 但全角英文显示效果其实是很差的, 下面是全角英文的一个示例:
hello, world
显得非常不紧凑, 最终, 一种能兼容 ASCII 的存储方案得到了广泛采纳, 这就是所谓的机内码了.
机内码
将国标码高低字节分别加上 0x80(=128)就得到了机内码(有时又叫交换码). 128 的二进制形式为10000000, 加 128, 简单地讲, 就是把国标码最高位置成 1. 至于为什么要这样呢? 我想你应该也清楚了, 就是要兼容 ASCII, ASCII 最高位为 0, 国标码加 128 后, 高低字节的最高位都成了 1, 这样就与 ASCII 区分开来.
将"啊"的国标码 3021 分别加上 0x80, 0x30+0x80=0xB0, 0x21+0x80=0xA1, 所以 B0A1 即是机内码.
如果从区位码算起, 那么则是加上 0x20+0x80=32+128=160=0xA0, 也即区位码的区和位分别直接加上 0xA0 即可得到机内码, 如下图所示:
如果你新建一个文本文件, 录入"啊"字, 以 GB2312 编码方式保存(使用 GBK 即可, 它兼容 GB2312), 再用十六进制查看, 你会发现使用的是机内码:

使用代码的测试也可验证这一点:
@Test
public void testAh() throws UnsupportedEncodingException {
String ah = "啊";
assertThat(DatatypeConverter.printHexBinary(ah.getBytes("GB2312"))).isEqualTo("B0A1");
}
虽然我们常把 GB2312 称为国标码, 但我们应该清楚, 实际存储使用的是机内码, 通常说到 GB2312 编码时指的就是这个机内码了. 它能兼容 ASCII, 是一种变长的编码方案, 对 ASCII 中的字符(也即所谓的"半角西文字符")采用一字节编码, 最高位为 0;对区位表中的字符采用两字节编码, 且每字节最高位均为 1, 以此区分.
自然, 全角英文字符就是两字节编码了, 跟汉字是一样的.
下面是一个混合了汉字, 半角字母 a 和全角字母a的编码示例, 共 5 个字节:

我们说 GB2312 是一个变长编码方案, 是站在其兼容 ASCII 编码角度而言, 就其方案标准本身定义的字符而言, 它是一个双字节定长编码方案.
你可能会想, 那国标码还有什么用?
我个人觉得, 国标码既然称为中文信息交换的标准码, 必然要成为"机内"码才有意义, 只不过由于各种原因, 最终未能如愿. 早期的一些系统或者一些小型的嵌入式系统或许采纳了它做为"机内"码. 当然以上为个人猜测, 仅供参考.
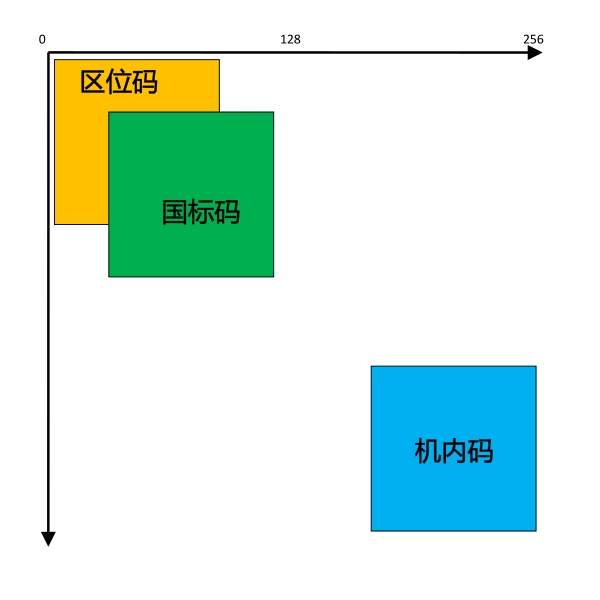
下面是三种码在 256×256 坐标中的位置的一个示意图: