Unicode UTF-X 编码
在对 Unicode 的码点, 平面都有了一定的了解后, 我们要触及一个重要的方面, 那就是码点到最终编码的转换, 在 Unicode 中, 这称为 UTF.
什么是 UTF?
UTF 即是 Unicode 转换格式(Unicode (or UCS) Transformation Format).
关于 UCS: Universal Character Set(统一字符集), 也称 ISO/IEC 10646 标准, 不那么严格的情况下, 可以认为它和"Unicode字符集"这一概念是等价的. 如有兴趣的可以自行搜索了解.
码点如何转换成 UTF 的几种形式呢? 我想这是大家很关心的问题, 再发一次前面的一个图:
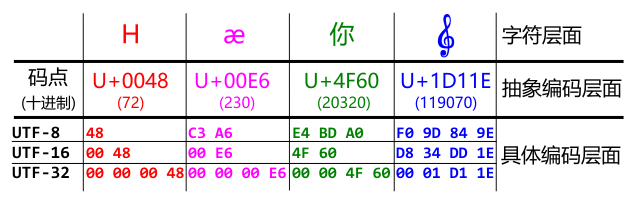
转换方式总共有三种:
- UTF-8
- UTF-16
- UTF-32
让我们先从最简单的 UTF-32 说起.
UTF-32
我们说码点最大的 0x10FFFF 也就 21 位, 而 UTF-32 采用的定长四字节则是 32 位, 所以它表示所有的码点不但毫无压力, 反而绰绰有余, 所以只要把码点的表示形式以前补 0 的形式补够 32 位即可. 这种表示的最大缺点是占用空间太大.
再来看稍复杂一点的 UTF-8.
UTF-8
UTF-8 是变长的编码方案, 可以有 1, 2, 3, 4 四种字节组合. 在前面的 定长与变长编码 篇章我们提到 UTF-8 采用了高位保留方式来区别不同变长, 如下:

如上, 彩色的表示是保留的固定位, X 表示是有效编码位.
单字节最高位都是 0, 多字节的最高位都是 1.
多字节方面, 更具体的讲, N 字节模式, 首字节以 "N 个 1 再加 0 " 打头, 后跟 "N-1" 个以 "10" 打头的字节.
码点与字节如何对应?
哪些码点用哪种变长呢? 可以先把码点变成二进制, 看它有多少有效位(去掉前导0)就可以确定了.
- 一字节有效编码位有 7 位, 27=128, 码点 U+0000 ~ U+007F(0~127)使用一字节.
一字节留给了 ASCII, 所以 UTF-8 兼容 ASCII.
- 二字节有效编码位只有 5+6=11 位, 最多只有 211=2048 个编码空间, 所以数量众多的汉字是无法容身于此的了. 码点 U+0080 ~ U+07FF(128~2047)使用二字节.
注意: 这里码点从 128~2047, 因为去掉了一字节的码点, 所以不会占满 2048 个编码空间, 是有冗余的, 但你不能把适用于一字节的码点放到这里来编码. 下同.
- 三字节模式可看到光是保留位就达到 4+2+2=8 位, 相当于一字节, 所以只剩下两字节 16 位有效编码位, 它的容量实际也只有 65536. 码点 U+0800~U+FFFF(2048~65535)使用三字节编码.
我们前面说到, 一些汉字字典收录的汉字达到了惊人的 10 万级别. 基本上, 常用的汉字都落在了这三字节的空间里, 这就是我们常说的汉字在 UTF-8 里用三字节表示.
当然了, 这么说并不严谨, 如果这 10 万的汉字都被收录进来的话, 那些偏门的汉字自然只能被挤到四字节空间上去了.
- 四字节的可以看到它的有效位是 3+6+6+6=21 位, 前面说到最大的码点 10FFFF 也是 21 位, U+FFFF 以上的增补平面的字符都在这里来表示.
按照 UTF-8 的模式, 它还可以扩展到 5 字节, 乃至 6 字节变长, 但 Unicode 说了码点就到 10FFFF, 不扩充了, 所以 UTF-8 最多到四字节就足够了.
码点到 UTF-8 如何转换?
那么具体是如何转换呢, 其实不难, 来看一个汉字"你"(U+4F60)的转换示意, 如下图所示:

上图显示了一有效位为 15 位的码点到三字节转换的一个基本原理, 我们还可看到原来 4F60 中的一头一尾的两个 4 和 0 在转换后还存在于最终的三字节结果中.
UTF-8 三字节模式固定了 1110 的开头模式, 所以多数汉字总是以 1110 开头, 换成 16 进制形式, 1110 就是字母 E.
如果看到一串的 16 进制有如下的形式: EX XX XX EX XX XX… 每三个三个字节前面都是 E 打头, 那么它很可能就是一串汉字的 UTF-8 编码了.
其它变长字节转换道理也类似, 其中分组从低位开始, 高位如不足则补零. 这里就不再示例了.
最后来看最复杂的 UTF-16, 在此之前我们先要理解代理区与代理对等概念.
UTF-16
UTF-16 是一种变长的 2 或 4 字节编码模式. 对于 BMP 内的字符使用 2 字节编码, 其它的则使用 4 字节组成所谓的代理对来编码.
什么是代理区?
在前面的鸟瞰图中, 我们看到了一片空白的区域, 这就是所谓的 代理区(Surrogate Area) 了, 代理区是 UTF-16 为了编码增补平面中的字符而保留的, 总共有 2048 个位置, 均分为 高代理区(D800–DBFF) 和 低代理区(DC00–DFFF) 两部分, 各 1024 大小.
这两个区一横一纵组成一个二维的表格, 共有 1024×1024=210×210=24×216=16×65536 个位置, 所以它恰好可以表示增补的 16 个平面中的所有字符.
当然了, 说恰好是不对的, 显然代理区就是冲着表示增补平面来设计的, 或者至少它们是一起考虑的.
下面的图片来自 wiki:
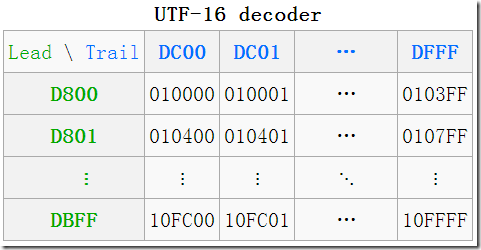
什么是代理对?
一个高代理区(即上图中的 Lead(头), 行)加一个低代理区(即上图中的 Trail(尾), 列)的编码组成一对即是一个 代理对(Surrogate Pair), 必须是这种先高后低的顺序, 如果出现两个高, 两个低, 或者先低后高, 都是非法的.
在图中可以看到一些转换的例子, 如:
- (D800 DC00)—> U+10000, 左上角, 第一个增补字符
- (DBFF DFFF)—> U+10FFFF, 右下角, 最后一个增补字符
码点到 UTF-16 如何转换?
分成两部分:
- BMP 中直接对应, 无须做任何转换;
- 增补平面 SP 中, 则需要做相应的计算.
其实由上图中的表也可看出增补平面中, 码点就是从上到下, 从左到右排列过去的, 所以只需做个简单的除法, 拿到除数和余数即可确定行与列.
拿到一个码点, 先减去 1000016, 再除以 40016(=102410)就是所在行了, 余数就是所在列了, 再加上行与列所在的起始值, 就得到了代理对了.
- Lead = (码点 - 1000016) ÷ 40016 + D800
- Trail = (码点 - 1000016) % 40016 + DC00
下面以前面的 U+1D11E 具体示例了代理对的计算:
- Lead = (1D11E - 1000016) ÷ 40016 + DB00 = D11E ÷ 40016 + D800 = 34 + D800 = D834
- Trail = (1D11E - 1000016) % 40016 + DC00 = D11E % 40016 + DC00 = 11E + DC00 = DD1E
所以, 码点 U+1D11E 对应的代理对即是 D834 DD1E.
注意: 以上计算方式仅用于说明转换原理, 不代表实际采用的计算方式.
一个码点减去 1000016 后实际最多只有 20 位, 再除以40016(=210=100000000002), 这个除数实际是一个二进制整数, 相当于十进制中整十整百的数.
所以结果实际上低 10 位上的就是余数, 而高 10 位(或者不到 10 位)上的就是商, 可以通过更为快速的 移位 操作实现.
举个十进制的例子, 就好比是 "1234÷100=12...34", 你都不需要拿笔去算.
应该说, 代理区的设计是有效率上的考虑的, 如果我们要做转换, 应该考虑是否有系统 API 可供调用, 而不要自行去实现.