Unicode 字符集
前面谈到不少的 Unicode, 但一直没有系统地谈及 Unicode 的方方面面, 所以本篇文章专门谈谈 Unicode, 当然了, Unicode 是一个庞大的主题, 这里也是拣些重要的方面谈谈而已, 免不了挂一漏万.
什么是 Unicode?
按 Unicode 官方的说法, Unicode 是 Unicode Standard(Unicode标准)的简写, 所以 Unicode 即是指 Unicode 标准.
按 wiki 的说法, 它是一个计算机工业标准(a computing industry standard).
下图来自 http://www.unicode.org/standard/WhatIsUnicode.html 中的截图, 在这里我把中文和英文的合在一起

这样一个所谓的一个唯一的数字在 Unicode 中就叫做 码点.
Unicode 中的码点是什么?
字符集通常又叫 编码字符集(coded charset), 这里的 coded 与 字符集编码(charset encoding) 中的 encoding 是不同的.
一个是 code, 一个是 encode, 翻译时都可以译成"编码", 但把 coded charset 译成 编号字符集 也许更不易引发误解.
- 码点(Code Point) 即是这里的 code, 表示的是一种抽象的数字编号.
- UTF-X 则是最终的 encoding.
这点如不明白, 仍请参见 编号与编码
码点的表示形式与范围是?
U+[XX]XXXX 是码点的表示形式, X 代表一个十六制数字, 可以有 4-6 位, 不足 4 位前补 0 补足 4 位, 超过则按是几位就是几位.
以下是码点的一些具体示例:
- U+0048
- U+4F60
- U+1D11E
注: 最后一个是5位的码点.
有人可能以为码点只有 4 位, 并常常将它与 UTF-16 的编码搞混, 这些都是对码点的误解.
它的范围目前是 U+0000 ~ U+10FFFF, 理论大小为 10FFFF+1=11000016. 后一个 1 代表是 65536, 因为是 16 进制, 所以前一个 1 是后一个 1 的 16 倍, 所以总共有1×16+1=17 个的 65536 的大小, 粗略估算为 17×6万=102万, 所以这是一个百万级别的数.
准确的值是 1114112, 一般记为 111 万左右即可.
16 进制的 110000 写成二进制是 100010000000000000000, 是一个 21 位的二进制数, 我们知道 210=K, 220=K×K=M, 即百万级别, 所以 221 理论上限是两百万左右.
100010000000000000000 大小基本上由第一个 1 决定, 所以也就一百万左右, 从这里也可印证前面的估算.
按照 Unicode 官方的说法, 码点范围就这些了, 以后也不会再扩充了.
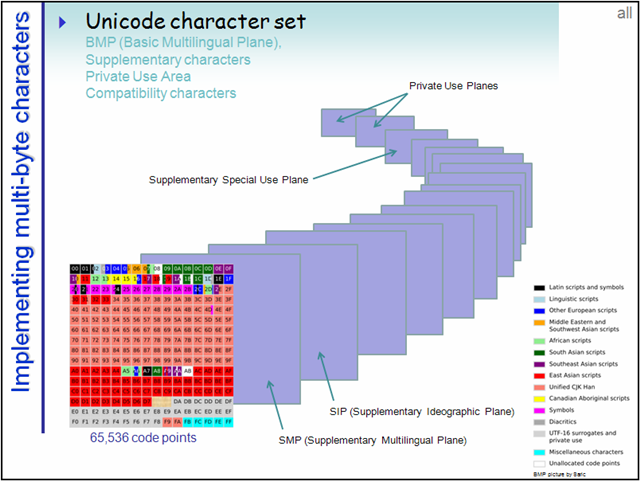
为了更好分类管理如此庞大的码点数, 把每 65536 个码点作为一个 平面, 总共 17 个平面.
平面, BMP, SP
什么是平面?
由前面可知, 码点的全部范围可以均分成 17 个 65536 大小的部分, 这里面的每一个部分就是一个 平面(Plane). 编号从 0 开始, 第一个平面称为 Plane 0.
下图来自http://rishida.net/docs/unicode-tutorial/part2
什么是 BMP?
第一个平面即是 BMP(Basic Multilingual Plane 基本多语言平面), 也叫 Plane 0, 它的码点范围是 [U+0000 ~ U+FFFF]. 这也是我们最常用的平面, 日常用到的字符绝大多数都落在这个平面内.
上图中第一个花花绿绿的平面就是 BMP.
UTF-16 只需要用两字节编码此平面内的字符.
很多人错误地把 UTF-16 当成定长两字节看待, 但只要处理的字符都在这一平面内, 一般也不会遇到什么问题.
什么是增补平面?
后续的 16 个平面称为 SP(Supplementary Planes). 显然, 这些码点已经是超过 U+FFFF 的了, 所以已经超过了 16 位编码空间的理论上限, 对于这些平面内的字符, UTF-16 采用了四字节编码.
注: 其中很多平面还是空的, 还没有分配任何字符, 只是先规划了这么多.
另: 有些还属于私有的, 如上图中的最后两个 Private Use Planes, 在此可自定义字符.
另: BMP 中也保留了部分区域供自定义字符使用.
鸟瞰 BMP 字符集
Unicode 的字符如此之多, 即使是最常用的 BMP, 它的码点空间也有 6 万多, 如果把这些字符都放到一张图片上, 会是什么情况呢? GNU Unifont 就制作了一张这样的图片. 见http://unifoundry.com/pub/unifont-7.0.03/unifont-7.0.03.bmp
提示: 打开它需要一点时间, 它的像素是 4000×4000 这个级别!
下图是它的一个缩略版本:

这是一个 256×256=65536 的表格, 横向纵向以 16 进制算都是从 00~FF(0~255).
CJK 统一汉字
你可能已经注意到上图中间一大片的区域, 没错, 它就是我们的汉字, 在 Unicode中, 称为 CJK 统一汉字(CJK: Chinese, Japanese, and Korean, 中日韩). 我们可以局部放大看一下:

正则表达式 [\u4E00-\u9FA5] 来匹配中文的问题在哪?
你可能在不少地方见过这种写法, 严格来说这只是 Unicode 最主要的一段中文区域.
你只要稍加计算就可知这一段大小不过是两万多一点, \u4E00-\u9FA5(19968-40869), 中文怎么可能只有这两万多字呢?
这里的"天字第一号"字 4E00 是哪个字呢? 请看上面的图中左边第 4E 开头的行, 它就是"一"字, 我们还可以看到它上面还有不少偏门的汉字, 这就是后来增补的汉字了. 所以严格来说, 这个上限是不准确的. 那么它的下限又是否准确呢? 下面是 Word 的一个插入符号功能的一个截图:
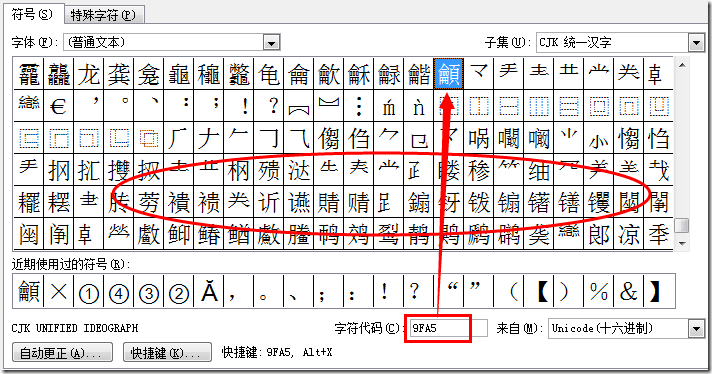
可以看到 9FA5 后面也还有不少的汉字, 它们中间又还夹杂着一些符号, 所以想正确地表示 Unicode 中的汉字还是个不小的挑战.
应该说, Unicode 处在不断发展中, 它有一百多万的空间, 目前也只是定义了十万左右的字符, 还会不断增加, 汉字自然也有可能增加, 所以汉字的范围实际上是动态的, 变化的.
当然了, 常用的基本落在了这一范围内, 而事实上已经包含了许多的不常用汉字, 毕竟连只有 6 千多字的 GB2312 中都含有大量的不常用汉字.
在要求不那么严格的应用中, 按以上范围去判断基本也 OK, 而汉字这一概念实际上也没有准确定义, 比方说上图中一些"偏旁部首", 这些是"汉字"吗?
代理区
你可能还注意到前面的 BMP 缩略图中有一片空白, 这白花花一片亮瞎了我们的猿眼的是啥呢? 正如标题已经告诉你的, 这就是所谓的 代理区(Surrogate Area) 了.
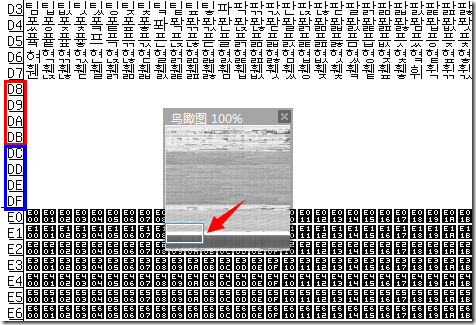
可以看到这段空白从 D8~DF. 其中前面的红色部分 D800–DBFF 属于 高代理区(High Surrogate Area), 后面的蓝色部分 DC00–DFFF 属于 低代理区(Low Surrogate Area), 各有四行, 大小均为 4×256=1024.
关于代理区的相关用途, 我们在讲到 UTF-16 编码时再说.
还可以看到在它之前是韩文的区域, 之后 E0 开始到 F8 的则是属于私有的(private), 可以在这里定义自己专用的字符.
前面说到 17 个平面的最后两个是私有平面, 这里的 U+E000 ~ U+F8FF 则是 BMP 平面中的私有区域(Private Use Area).